该不该从零开始预训练一个千亿级大模型?
这个问题从 2023 年 ChatGPT 破圈之后就一直成为行业人士的 Top 讨论话题之一。不久前,国内也有报道号称排名前六的“大模型六虎”中至少有两家已经放弃大模型的预训练、转向 AI 应用,零一万物就是其中之一。
背后原因无他:预训练的成本高,企业“算不过来账”。
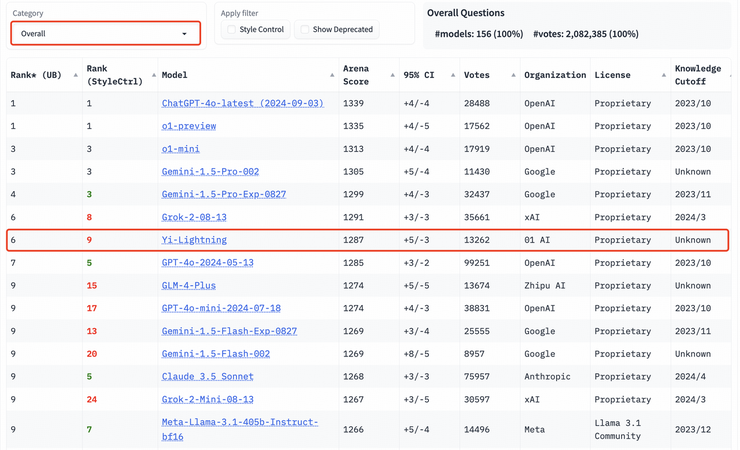
但就在今天,继千亿参数模型 Yi-Large 之后,零一万物又发布了新的预训练旗舰模型 Yi-Lightning(号称“闪电”),在国际权威盲测榜单 LMSYS 上超越了 OpenAI 今年 5 月发布的 GPT-4o、Anthropic Claude 3.5 Sonnet,排名世界第六,中国第一。
这是在 LMSYS 这一全球大模型必争的公开擂台上,中国大模型首度实现超越 OpenAI GPT-4-2024-05-13!
根据榜单排名,零一万物紧随 OpenAI、Google 之后,与 xAI 打平,进击全球前三大模型企业,以优异模型性能稳居世界第一梯队大模型公司之列。
模型性能升级之余,Yi-Lightning 的推理速度也有大幅提升,首包时间较上半年发布的 Yi-Large 减少一半。最高生成速度提速近四成,堪称“极速”。
同时,Yi-Lightning 还在保持高性能的同时,实现了推理成本的进一步下降,每百万 token 仅需 0.99 元,直逼行业最低价,以极致性价比助力开发者与企业客户轻松实现 SOTA 大模型自由。
目前 Yi-Lightning 已上线 Yi 大模型开放平台:
https://platform.lingyiwanwu.com/。
在李开复看来,虽然中国在大模型的预训练上落后于美国,但不代表中国大模型公司会放弃“预训练”这一战略级步骤。另外,中国的大模型在预训练速度上其实没有比美国落后很多,以 OpenAI 为例:今年 5 月 13 日 OpenAI 发布GPT-4o-2024-05-13,零一万物 Yi-Lightning 在今年 10 月就超过了 GPT-4o-2024-05-13,仅五个月的时间差。
缩短时间差,是因为零一万物在各个维度的人才储备与知识积累上都足够扎实。
预训练的门槛很高,需要团队具备芯片人才、推理人才、基础架构人才、算法人才等。由此来看,并不是所有的大模型公司都具备大模型预训练的条件。对于这些公司来说,放弃预训练其实是明智的选择;但零一万物从创业的第一天起就坚持“模基共建”、“模型+Infra+应用”三体合一,没有放弃的理由。
此外,Yi-Lightning 打平了 xAI 的 Grok。xAI 在训练 Grok 时号称用了几万张 GPU,但零一万物透露,他们此次发布的 Yi-Lightning 训练只用了两千张 GPU、训练了一个半月,只花了 300 多万美金。也就是说,零一万物用了 xAI 的 2% 左右的成本就打平了 Grok。
零一万物的特点是“模基共建”。他们不仅追求模型的性能,也追求模型的推理成本,而 AI infra 与上层模型的同步优化是实现这一目标的关键手段。
LMSYS 评测:性能超越 GPT-4o
LMSYS Org 发布的 Chatbot Arena 凭借着新颖的“真实用户盲测投票”机制与 Elo 评分系统,已成为全球业界公认最接近真实用户使用场景、最具用户体感的“大模型奥林匹克”。
随着 Yi-Lightning 的加入,LMSYS ChatBot Arena 总榜排名再次发生震荡。在 LMSYS 总榜上,Yi-Lightning 的最新排名胜过硅谷头部企业 OpenAI、Anthropic 发布的 GPT-4o-2024-05-13、 Claude 3.5 sonnet,在一众国内大模型中拔得头筹,超越 Qwen2.5-72b-Instruct、DeepSeek-V2.5、GLM-4-Plus 等。
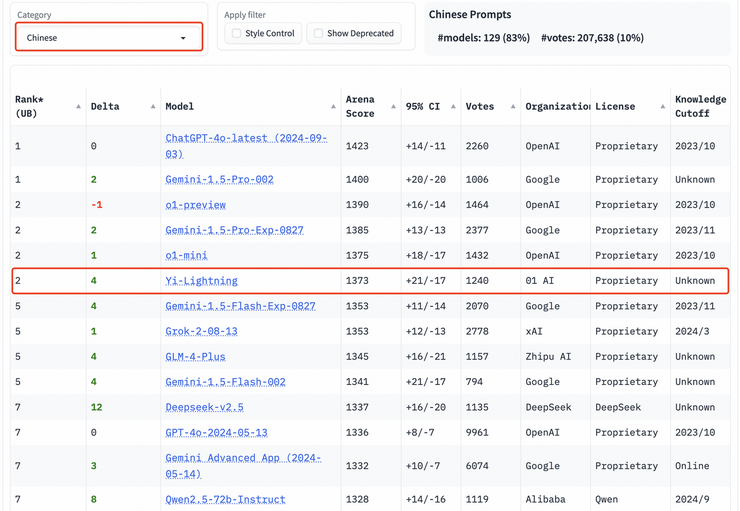
在众多分榜上,Yi-Lightning 的成绩同样出众。在中文分榜上,Yi-Lightning 超越了 xAI 发布的 Grok-2-08-13、智谱发布的 GLM-4-Plus 等国内外优质模型,与 o1-mini 等模型并列排名世界第二。
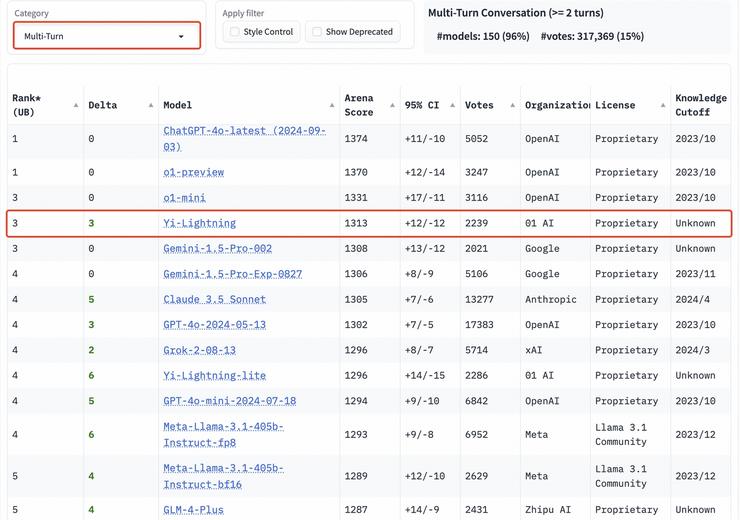
在多轮对话分榜上,Yi-Lightning 则是超越了 Google 所发布的 Gemini-1.5-Pro 、Anthropic 发布的 Claude 3.5 Sonnet 等知名旗舰模型,排名第三。
数学能力,代码能力方面,Yi-Lightning 同样处于全球第一梯队。在数学、代码分榜上,Yi-Lightning分别取得第三、第四名。
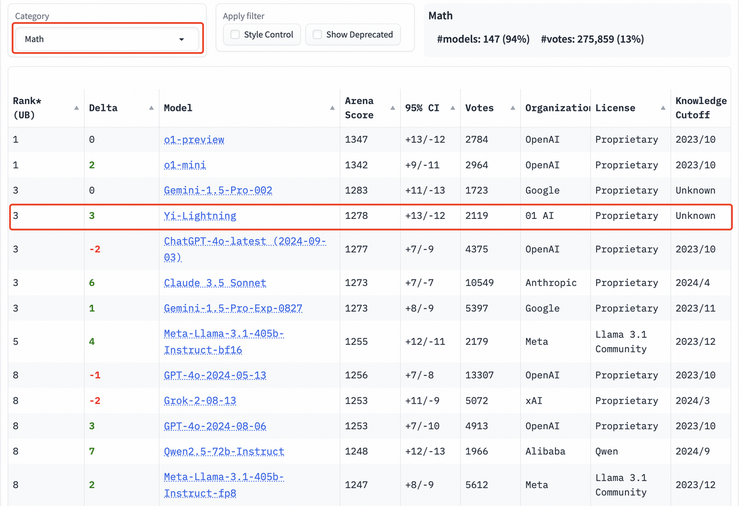
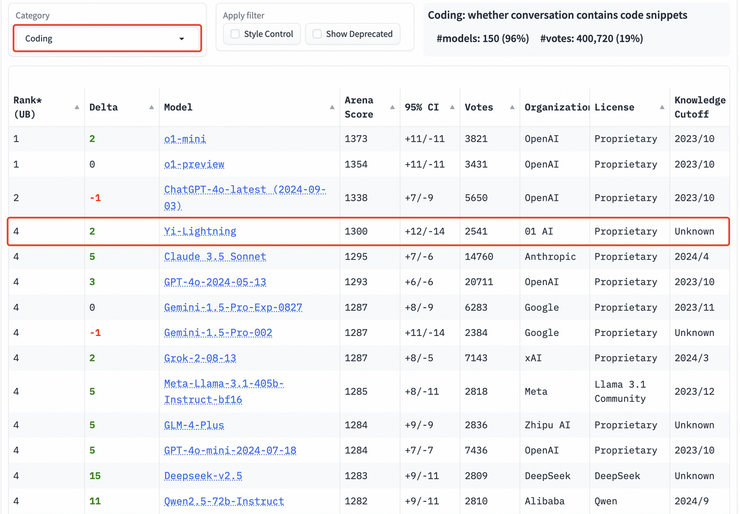
以专业性与高难度著称的艰难提问、长提问榜单上,Yi-Lightning 的表现依旧出众,均取得世界第四的优异成绩。
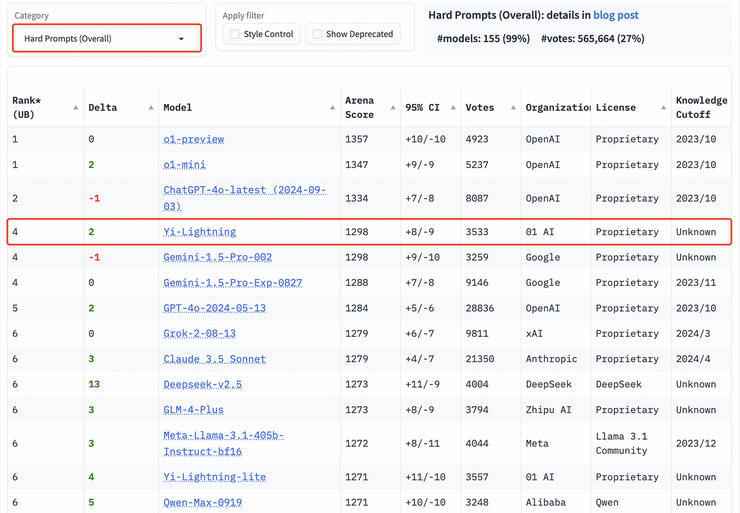

LMSYS Chatbot Arena 的用户体验评估体现了 Yi-Lightning 的出色性能,也更为直观地验证了大模型解决真实世界问题的能力。
换言之,Yi-Lightning 能够丝滑地由实验室场景过渡到模拟真实用户场景,能够更快、更高质量地实现模型能力落地。
作为模型落地的典型场景之一,翻译场景十分全面地考验了模型语言理解和生成、跨语言能力、上下文感知能力,通过 Yi-Lightning 与 Qwen2.5-72b-Instruct、DeepSeek-V2.5、Doubao-pro 的对比,Yi-Lightning 优异的模型性能也得到了最直观的展现:

推理速度飞升生成速度较 Yi-Large 最高提升近四成
从命名可以看出,与 Yi-Large 相比,Yi-Lightning 在模型性能更进一步的前提下,推理速度方面有着极大提升。
这一方面得益于零一万物自身世界一流的 AI Infra 能力,另一方面则是由于,与此前稠密模型架构不同,Yi-Lightning 选择采用 Mixture of Experts(MoE)混合专家模型架构,并在模型训练过程中做了新的尝试。
内部评测数据显示,在 8xH100 算力基础下,以同样的任务规模进行测试,Yi-Lightning 的首包时间(从接收到任务请求到系统开始输出响应结果之间的时间)仅为 Yi-Large 的一半,最高生成速度也提升了近四成,大幅实现了旗舰模型的性能升级。
外部模型中,零一万物选择与 GPT-4o 支持下的 ChatGPT 做对比。仅凭肉眼就可以看出,Yi-Lightning 的生成速度,堪称“极速”。
如何在保持模型性能接近最优的同时,尽可能减少激活参数的数量以降低训推成本、提升推理速度,是 MoE 模型训练的重点目标。具体到 Yi-Lightning 模型的训练,零一万物的模型团队进行了如下尝试,并取得了正向反馈:
1.独特的混合注意力机制(Hybrid Attention)
此前关注 MoE 架构的大模型公司,如 Mistral AI ,大多采用了 Sliding Window Attention(滑动窗口注意力机制)。这种机制通过在输入序列上滑动一个固定大小的窗口来限制每个位置的关注范围,从而减少计算量并提高模型的效率和可扩展性。但是同样受限于固定窗口,模型可能无法充分考虑序列中较远位置的信息,导致信息理解不完整。
在 Yi-Lightning 的训练过程中,零一万物采用了混合注意力机制(Hybrid Attention)。这种机制只在模型的部分层次中将传统的全注意力(Full Attention)替换为滑动窗口注意力(Sliding Window Attention),旨在平衡模型在处理长序列数据时的性能和计算资源消耗。通过这种方式,Yi-Lightning 能够在保持模型对长序列数据的高效处理能力的同时,降低计算成本。
结合这两项技术,零一万物成功地将 Yi-Lightning 模型在面对长序列数据时的表现保持在较高水平,同时显著降低了 KV 缓存的大小,实现了 2 倍至 4 倍的减少;某些层次的计算复杂度也由序列长度的平方级降低到线性级,进一步提高了模型的计算效率。这些改进使得 Yi-Lightning 模型本身在处理长序列数据时更加高效。
基于模基共建战略,零一万物在 AI Infra 方面也做出了进一步优化,结合 Yi-Lightning 的自身特性,共同确保了模型即便在资源受限的环境下也能够保持稳定、出色的表现。
2. 动态 Top-P 路由
面对简单的任务,MoE 模型可选择激活较少的专家网络以加快推理速度,同时保持良好的性能;面对更复杂的任务,MoE 模型则可以激活更多的专家网络可以提高模型的准确性。
动态 Top-P 路由就像是 MoE 模型中做出选择的“把关人”。它可以根据任务的难度动态自动选择最合适的专家网络组合,而无需人工干预。与传统的 Top-K 路由机制相比,动态 Top-P 路由能够更灵活地根据任务的难度调整激活的专家网络数量,从而更好地平衡推理成本和模型性能。
在 Yi-Lightning 训练过程中,零一万物选择引入动态 Top-P 路由机制,这使得 Yi-Lightning 能够更加智能地适应各种任务需求,这也是它能够实现“极速推理”的一大原因。
3. 多阶段训练(Multi-stage Training)
在 Yi-Lightning 的训练规划中,零一万物还改进了单阶段训练,使用了多阶段的训练模式。据介绍,在训练前期,零一万物模型团队更加注重数据的多样性,希望 Yi-Lightning 在这个阶段尽可能广泛地吸收不同的知识;而在训练后期则会更加侧重内容更丰富、知识性更强的数据。
通过这种各有侧重的方式, Yi-Lightning 得以在不同阶段吸收不同的知识,既便于模型团队进行数据配比的调试工作,同时在不同阶段采用不同的 batch size 和 LR schedule 来保证训练速度和稳定性。
结合多阶段的训练策略,辅之以自创高质量数据生产管线,零一万物不仅可以保证 Yi-Lightning 的训练效率,还可以让 Yi-Lightning 在具备丰富知识的同时,基于复杂且重要的数据做进一步的强化。此外,在有较多新增数据、或者想要对模型进行专有化时,零一万物也可以基于 Yi-Lightning 进行快速、低成本的重新训练。相较于传统的单阶段训练,这样的训练方法既可以保证模型整体的训练效果,同时也能更高效地利用训练数据。
闪电秘诀:“模型+AI Infra+应用”三体布局
国内大模型赛道狂奔进入第二年,商业化造血能力已经成为多方关注的焦点。而无论是 ToC 还是 ToB,如何提前预判 TC-PMF 是绕不开的核心命题。模型性能与推理成本,两项关键因素直接影响着大模型落地的成败。
Yi-Lightning 已在 LMSYS 等多项国际权威评测中取得 SOTA 成绩,同时支持极速推理,模型性能已得到验证。而基于 MoE 模型架构与零一万物的 AI Infra 优势,Yi-Lightning 的推理成本也降至行业新低。
目前, Yi-Lightning 已经上线 Yi 大模型开放平台(https://platform.lingyiwanwu.com/),每百万 token 仅需 0.99 元,直逼行业最低价,支持开发者与企业客户轻松实现 SOTA 大模型自由。
基于模型性能显著升级、推理成本大幅下降、同时可实现极速推理的 Yi-Lightning,零一万物可探索的落地场景将会进一步扩展。
10月16日,零一万物也首度对媒体公布了全新 ToB 战略下的首发行业应用产品 AI 2.0 数字人,聚焦零售和电商等场景,将最新版旗舰模型实践到行业解决方案,在弹幕互动、商品信息提取、实时话术生成等环节,AI 2.0 数字人已接入 Yi-Lightning。接入 Yi-Lightning 后,数字人的实时互动效果更好,话术更丝滑,回复也更准确;业务数据方面,在接入 Yi-Lightning 全新加持的数字人直播后,某酒旅企业的 GMV 较此前上升 170%。
,时长00:46Yi-Lightning数字人对比视频同时, Yi-Lightning 的“极速”不仅体现在模型推理速度,定制模型的交付速度也会得到极大提升。受益于 MoE 模型的自身特性、在多阶段训练方面的技术积累,零一万物能够基于客户的特殊需求,进行高效地针对性训练,快速交付贴合特定服务场景、极速推理、成本极低的私有化定制模型。
打造新质生产力
进入2024年以来,中国大模型行业从狂奔进入到了“长跑阶段”,从技术侧和产业侧都引发了行业的进一步思考。
从技术发展上看,在算力受限的情况下,中国基座模型的研发能力处在世界什么身位,如何追赶国外顶尖大模型等问题引发外界关注。甚至一度传出“中国可以不用再研发预训练基座模型”的说法。
零一万物此次推出的Yi-Lightning模型一经亮相,就在世界权威的盲测榜单LMSYS中击败了OpenAI今年五月发布的GPT-4-2024-05-13。中国大模型首度超越性能极佳的 GPT-4-2024-05-13 对于我国人工智能发展是个里程碑事件,彰显了中国所孕育的强大技术实力。
根据线上成果展示,零一万物的 Yi-Lightning 翻译莎士比亚的作品,只要 5 秒钟;其他模型是 Yi-Lightning 的 2 到 3 倍。
这些都彰显了中国大模型公司“模型+基础设施+应用”“三位一体”全栈式布局的必要性和重要性。
GPT-4o 之后,o1 的发布是一种新技术范式的开始,代表着大模型的重点从预训练到推理。接下来零一万物也会朝着这个方向去发展。
AGI 仍在远方,现阶段更需要让大模型能力落地应用层, 推动整个大模型行业形成健康的生态。
在这一阶段,零一万物会坚持“模型+AI Infra+应用”三位一体的全栈式布局,以国际 SOTA 的基座模型为基础,积极在 ToB 企业级解决方案上探索 TC-PMF,以更从容的姿态迎接即将到来的 AI 普惠时代。
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。